linux 服务器性能监控(一)
原文链接: https://www.cnblogs.com/insane-Mr-Li/p/10727921.html
这篇文章主要介绍一些常用的linux服务器性能监控命令,包括命令的常用参数、指标的含义以及一些交互操作。
几个问题
命令本身并不复杂,关键是你对操作系统基础知识的掌握和理解,先来看看下面几个问题:
CPU、内存以及硬盘的关系是怎样的?
进程和线程是什么?有什么区别?有什么优缺点?
什么是物理内存?什么是虚拟内存?什么时候要用到虚拟内存?
什么是CPU中断?CPU上下文切换?CPU缺页计算?
怎么理解系统负载?如何通过load average的值来判断系统负载是否过高?
...
相信基础好的司机心里已经有个大致的答案,那如果你一知半解,请仔细阅读全文,部分答案会在相关的命令讲解中揭晓。对于理解错误或者不到位的地方希望老司机不吝赐教。
free
free 命令是监控linux 内存使用最常用的命令,参数[-m]表示以M 为单位查看内存使用情况(默认为kb)。
[root@localhost ~]# free -m total used free shared buffers cached Mem: 482 130 352 0 9 36 -/+ buffers/cache: 83 399Swap: 991 0 991
Mem:物理内存大小。
total:总计物理内存的大小。
used:已使用多大。
free:可用有多少。
shared:多个进程共享的内存总额。
buffers:缓冲区内存总量。
cached:交换区缓冲区内存总量。
第三行(-/+ buffers/cached):系统的物理内存真实使用量,可通过used-buffers-cached计算得到,因为buffers和cached也是占用物理内存得来,可以通过释放它们来获得这部分内存。
Swap:交换区总量,也叫虚拟内存。
那么,什么是虚拟内存?

现在明白什么是虚拟内存,什么时候要用到虚拟内存了吧。所以,当你在监控linux操作系统的时候,如果发现系统使用了交换内存,那么说明系统的 ** 物理内存已经用完了**,需要排查是哪些程序占用了物理内存,对内存进行进一步的深入分析。还有一点要说的就是,交换内存的速度是非常慢的。
uptime
uptime 命令是监控系统性能最常用的一个命令,主要是来统计系统当前的运行状态,即负载情况。
[root@localhost~]# uptime 05:41:01 up 3 min, 1 user, load average: 0.23, 0.33, 0.15
输出信息依次是:系统现在的时间,系统从上次开机到现在运行了多长时间,系统当前有多少个登录用户,系统在1分钟内、5 分钟内、15 分钟内的平均负载。
如果load average值长期大于系统CPU的个数则说明CPU很繁忙,负载很高,可能会影响系统性能,导致系统卡顿响应时间长等等。
load average值与系统CPU的个数对比怎么理解?load average的值表示在单位时间内运行的进程数,而CPU一个内核同一时间只能处理一个进程,一台16核CPU的服务器如果load average大于16,那说明系统正处于超负荷运行状态。
vmstat
vmstat 可以对操作系统的内存信息、进程状态、CPU 活动、磁盘等信息进行监控,不足之处是无法对某个进程进行深入分析。
[root@localhost~]# vmstat 2 3 -S Mprocs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 235 11 88 0 0 32 2 21 23 0 1 98 1 0 0 0 0 235 11 88 0 0 0 0 16 19 0 0 100 0 0 0 0 0 235 11 88 0 0 0 0 13 19 0 0 100 0 0
2表示每2秒取样一次,3表示取数3次,-S表示单位,可选有 k 、K 、m 、M。
procs
R 列表示运行和等待 CPU 时间片的进程数,这个值如果长期大于系统 CPU 个数,说明CPU 不足,需要增加 CPU。
B 列表示在等待资源的进程数,比如正在等待 I/O 或者内存交换等。memory
swpd 列表示切换到内存交换区的内存大小(单位 KB),通俗讲就是虚拟内存的大小。如果 swap 值不为 0 或者比较大, 只要 si、so 的值长期为 0,这种情况一般属于正常情况
free 列表示当前空闲的物理内存(单位 KB) 。
buff 列表示 buffers cached 内存大小,也就是缓冲区大小,一般对块设备的读写才需要缓冲。
cache 列表示 page cached 的内存大小,也就是缓存大小,一般作为文件系统进行缓冲,频繁访问的文件都会被缓存,如果 cache 值非常大说明缓存文件比较多,如果此时 io中的 bi 比较小,说明文件系统效率比较好。swap
si 列表示由磁盘调入内存,也就是内存进入内存交换区的内存大小。
so 列表示由内存进入磁盘,也就是有内存交换区进入内存的内存大小。
一般情况下,si、so 的值都为 0,如果 si、so 的值长期不为 0,则说明系统内存不足,需要增加系统内存。io
bi 列表示由块设备读入数据的总量,即读磁盘,单位 kb/s。
bo 列表示写到块设备数据的总量,即写磁盘,单位 kb/s。
如果 bi+bo 值过大,且 wa 值较大,则表示系统磁盘 IO 瓶颈。system
in 列表示某一时间间隔内观测到的每秒设备中断数。
cs 列表示每秒产生的上下文切换次数。
这 2 个值越大,则由内核消耗的 CPU 就越多。cpu
us 列表示用户进程消耗的 CPU 时间百分比,us 值越高,说明用户进程消耗 cpu 时间越多,如果长期大于 50%,则需要考虑优化程序或者算法。
sy 列表示系统内核进程消耗的 CPU 时间百分比,一般来说 us+sy 应该小于 80%,如果大于 80%,说明可能处于 CPU 瓶颈。
id 列表示 CPU 处在空闲状态的时间百分比。
wa 列表示 IP 等待所占的 CPU 时间百分比,wa 值越高,说明 I/O 等待越严重,根据经验 wa 的参考值为 20%,如果超过 20%,说明 I/O 等待严重,引起 I/O 等待的原因可能是磁盘大量随机读写造成的, 也可能是磁盘或者此哦按监控器的贷款瓶颈 (主要是块操作)造成的。
vmstat命令的结果显示比较全面,可以看到操作系统的内存信息、进程状态、CPU 活动、磁盘等信息,不足之处是无法对某个进程进行深入分析。但是以上每一列的含义都是要重点掌握!具体的参数和用法在这里就不列举了,需要的可自行百度了解。
sar

好吧,我只是为了引起大家的注意。
sar 是非常强大性能分析命令,通过 sar 命令可以全面的获取系统的 CPU、运行队列、磁盘 I/O、交换区、内存、cpu 中断、网络等性能数据。老司机必备!
sar安装直接yum install -y sysstat,这里有个坑就是安装完成后直接使用的话会报错,提示文件不存在,解决办法是先执行sar -o 2 3,来生成所需文件,之后使用就正常啦。
sar监控CPU

[root@localhost~]# sar -u 2 3Linux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) 06时58分50秒 CPU %user %nice %system %iowait %steal %idle 06时58分52秒 all 0.00 0.00 0.50 0.00 0.00 99.5006时58分54秒 all 0.00 0.00 0.50 0.00 0.00 99.5006时58分56秒 all 0.00 0.00 0.50 0.00 0.00 99.50平均时间: all 0.00 0.00 0.50 0.00 0.00 99.50
2表示每2秒取样一次,3表示取数3次,-u表示CPU使用率。
%usr:用户进程消耗的 CPU 时间百分比。
%nice: 运行正常进程消耗的 CPU 时间百分比。
%system:系统进程消耗的 CPU 时间百分比。
%iowait:I/O 等待所占 CPU 时间百分比。
%steal:在内存紧张环境下,pagein 强制对不同的页面进行的 steal 操作。虚拟服务占用的CPU时间百分比,这个值一般为0.
%idle:CPU 空闲状态的时间百分比。
在所有的显示中,我们应主要注意%iowait 和%idle,%iowait 的值过高,表示硬盘存在 I/O 瓶颈, %idle 值高,表示 CPU 较空闲,如果%idle 值高但系统响应慢时,有可能是 CPU 等待分配内存, 此时应加大内存容量。%idle 值如果持续低于 10,那么系统的 CPU 处理能力相对较低,表 明系统中最需要解决的资源是 CPU。
[root@localhost~]# sar -q 2 3Linux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) 07时16分31秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-1507时16分33秒 0 118 0.16 0.07 0.0907时16分35秒 0 118 0.16 0.07 0.0907时16分37秒 0 118 0.15 0.07 0.09平均时间: 0 118 0.16 0.07 0.09
2表示每2秒取样一次,3表示取数3次,-q显示运行队列的大小,它与系统当时的平均负载相同。
runq-sz:运行队列的长度(等待运行的进程数) 。
plist-sz:进程列表中进程(processes)和线程(threads)的数量。
ldavg-1:最后 1 分钟的系统平均负载(System load average) 。
ldavg-5:过去 5 分钟的系统平均负载。
ldavg-15:过去 15 分钟的系统平均负载。
sar监控内存
[root@localhost~]# sar -r 2 3Linux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) 07时22分04秒 kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit 07时22分06秒 241108 269556 52.79 12736 90360 543584 21.1107时22分08秒 241108 269556 52.79 12736 90360 543584 21.1107时22分10秒 241108 269556 52.79 12736 90360 543584 21.11平均时间: 241108 269556 52.79 12736 90360 543584 21.11
2表示每2秒取样一次,3表示取数3次,-r显示显示系统内存使用情况。
kbmemfree: 这个值和 free 命令中的 free 值基本一致,所以它不包括 buffer 和 cache 的空间。
kbmemused:这个值和 free 命令中的 used 值基本一致,所以它包括 buffer 和 cache 的空间。
%memused:这个值是 kbmemused 和内存总量(不包括 swap)的一个百分比。
kbbuffers 和 kbcached:这两个值就是 free 命令中的 buffer 和 cache。
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap)。
%commit:这个值是 kbcommit 与内存总量(包括 swap)的一个百分比。
[root@localhost~]# sar -B 2 3Linux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) 07时26分26秒 pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff 07时26分28秒 0.00 0.00 18.91 0.00 52.24 0.00 0.00 0.00 0.0007时26分30秒 0.00 0.00 19.60 0.00 52.76 0.00 0.00 0.00 0.0007时26分32秒 0.00 5.97 15.42 0.00 52.24 0.00 0.00 0.00 0.00平均时间: 0.00 2.00 17.97 0.00 52.41 0.00 0.00 0.00 0.00
2表示每2秒取样一次,3表示取数3次,-B显示系统内存分页情况。
pgpgin/s:表示每秒从磁盘或 SWAP 置换到内存的字节数(KB)。
pgpgout/s:表示每秒从内存置换到磁盘或 SWAP 的字节数(KB)。
fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor)。
majflt/s:每秒钟产生的主缺页数。
[[root@localhost~]# sar -W 2 3Linux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) 08时31分10秒 pswpin/s pswpout/s 08时31分12秒 0.00 0.0008时31分14秒 0.00 0.0008时31分16秒 0.00 0.00平均时间: 0.00 0.00
2表示每2秒取样一次,3表示取数3次,-W显示系统虚拟内存分页情况。
pswpin/s:每秒系统换入的交换页面(swap page)数量。
pswpout/s:每秒系统换出的交换页面(swap page)数量。
sar监控I/O
[root@localhost~]# sar -b 2 3Linux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) 08时36分27秒 tps rtps wtps bread/s bwrtn/s 08时36分29秒 0.00 0.00 0.00 0.00 0.0008时36分31秒 0.00 0.00 0.00 0.00 0.0008时36分33秒 0.00 0.00 0.00 0.00 0.00平均时间: 0.00 0.00 0.00 0.00 0.00
2表示每2秒取样一次,3表示取数3次,-b显示缓冲区使用情况。
tps:每秒钟物理设备的 I/O 传输总量。
rtps:每秒钟从物理设备读入的数据总量。
wtps:每秒钟向物理设备写入的数据总量。
bread/s:每秒钟从物理设备读入的数据量,单位为 块/s。
bwrtn/s:每秒钟向物理设备写入的数据量,单位为 块/s。
sar监控文件和内核
[root@localhost~]# sar -v 2 3Linux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) 09时43分12秒 dentunusd file-nr inode-nr pty-nr 09时43分14秒 4466 768 11506 109时43分16秒 4466 768 11506 109时43分18秒 4466 768 11506 1平均时间: 4466 768 11506 1
2表示每2秒取样一次,3表示取数3次,-v显示进程、节点、文件和锁表状态。
inode-sz:目前核心中正在使用或分配的节点表的表项数,由核心参数 MAX-INODE 控制。
file-sz:目前核心中正在使用或分配的文件表的表项数, 由核心参数 MAX-FILE 控 制。
super-sz:溢出出现的次数。
dentunusd:目录高速缓存中未被使用的条目数量 。
sar监控设备使用情况
[root@localhost~]# sar -d 2 3Linux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) 09时37分46秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 09时37分48秒 dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.0009时37分48秒 dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.0009时37分48秒 dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
2表示每2秒取样一次,3表示取数3次,-d显示设备使用情况。
tps:每秒从物理磁盘 I/O 的次数.多个逻辑请求会被合并为一个 I/O 磁盘请求,一次传输的大小是不确定的。
rd_sec/s:每秒读扇区的次数。
wr_sec/s:每秒写扇区的次数。
avgrq-sz:平均每次设备 I/O 操作的数据大小(扇区)。
avgqu-sz:磁盘请求队列的平均长度。
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1 秒=1000 毫秒)。
svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间。
%util:I/O 请求占 CPU 的百分比,比率越大,说明越饱和。
avgqu-sz 的值较低时,设备的利用率较高。
当%util 的值接近 1% 时,表示设备带宽已经占满。
await-svctm=io等待时间。
sar总结
要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来
怀疑 CPU 存在瓶颈,可用 sar -u 和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
怀疑 I/O 存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
参数列表
-u:CPU 利用率
-v:进程、节点、文件和锁表状态。
-d:硬盘使用报告。
-q:显示运行队列的大小,它与系统当时的平均负载相同
-B:内存分页情况
-b:缓冲区使用情况。
-W:系统交换活动,虚拟内存。
iostat
iostat 是对系统的磁盘 I/O 操作进行监控,它的输出主要显示磁盘读写操作的统计信息,同时给出 CPU 的使用情况。同 vmstat 一样,iostat 不能对某个进程进行深入分析,仅对操作系统的整体情况进行分析。
iostat监控磁盘
[root@localhost~]# iostat -xLinux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 0.04 0.00 0.30 0.23 0.00 99.43Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await r_await w_await svctm %util sda 0.16 0.07 0.23 0.12 13.67 1.51 43.06 0.01 22.07 8.37 49.13 11.15 0.39dm-0 0.00 0.00 0.31 0.19 13.08 1.50 29.58 0.01 29.07 18.88 45.61 7.92 0.39dm-1 0.00 0.00 0.02 0.00 0.15 0.00 8.00 0.00 5.47 5.47 0.00 4.12 0.01
-x显示所有磁盘分区的情况。
rrqm/s:每秒进行 merge 的读操作数目,即 delta(rmerge)/s 。
wrqm/s:每秒进行 merge 的写操作数目,即 delta(wmerge)/s 。
r/s:每秒完成的读 I/O 设备次数,即 delta(rio)/s 。
w/s: 每秒完成的写 I/O 设备次数,即 delta(wio)/s 。
rsec/s:每秒读扇区数,即 delta(rsect)/s。
wsec/s:每秒写扇区数,即 delta(wsect)/s
rkB/s:每秒读 K 字节数,是 rsect/s 的一半,因为每扇区大小为 512 字节。
wkB/s:每秒写 K 字节数,是 wsect/s 的一半
avgrq-sz:平均每次设备 I/O 操作的数据大小 (扇区),即
delta(rsect+wsect)/delta(rio+wio) 。avgqu-sz:平均 I/O 队列长度,即 delta(aveq)/s/1000 (因为 aveq 的单位为毫秒)。
Await: 平均每次设备 I/O 操作的等待时间 (毫秒), 即 delta(ruse+wuse)/delta(rio+wio) 。
**Svctm:平均每次设备 I/O 操作的服务时间 (毫秒),即delta(use)/delta(rio+wio) **
%util:一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的,即 delta(use)/s/1000 (因为 use 的单位为毫秒) 。
[root@localhost~]# iostat -dLinux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn sda 0.35 13.40 1.50 212052 23818dm-0 0.49 12.82 1.50 202898 23800dm-1 0.02 0.15 0.00 2400 0
-d显示磁盘使用情况。
tps:每秒从物理磁盘 I/O 的次数.多个逻辑请求会被合并为一个 I/O 磁盘请求,一次传输的大小是不确定的。磁盘的一次读或者写都是一次 I/O 操作
Blk_read/s:每秒读取的数据块数。
Blk_wrtn/s :每秒写入的数据块数。
Blk_read:读取的所有块数。
Blk_wrtn :写入的所有块数。
iostat监控CPU
[root@localhost~]# iostat -c 2 3 Linux 2.6.32-573.22.1.el6.i686 (localhost) 2016年11月02日 _i686_ (1 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 0.04 0.00 0.29 0.24 0.00 99.43avg-cpu: %user %nice %system %iowait %steal %idle 0.00 0.00 0.00 0.00 0.00 100.00avg-cpu: %user %nice %system %iowait %steal %idle 0.00 0.00 0.50 0.00 0.00 99.50
-c显示系统CPU使用情况,2表示时间间隔2s,3表示取数3次。
%usr:用户进程消耗的 CPU 时间百分比。
%nice: 运行正常进程消耗的 CPU 时间百分比。
%system:系统进程消耗的 CPU 时间百分比。
%iowait:I/O 等待所占 CPU 时间百分比。
%steal:在内存紧张环境下,pagein 强制对不同的页面进行的 steal 操作。
%idle:CPU 空闲状态的时间百分比。
top
我想这个命令大家肯定已经相当熟悉,甚至有些童鞋有用过。top 命令能够实时监控系统的运行状态, 并且可以按照 CPU、 内存和执行时间进行排序,同时 top 命令还可以通过交互式命令进行设定显示,通过 top 命令可以查看即时活跃的进程。
top - 05:57:44 up 2 min, 1 user, load average: 0.47, 0.37, 0.15Tasks: 92 total, 1 running, 91 sleeping, 0 stopped, 0 zombie Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 99.3%id, 0.0%wa, 0.0%hi, 0.3%si, 0.0%st Mem: 510664k total, 268192k used, 242472k free, 11464k buffers Swap: 2064380k total, 0k used, 2064380k free, 90252k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 745 root 20 0 0 0 0 S 0.3 0.0 0:00.04 flush-253:0 1724 root 20 0 12468 3392 2640 S 0.3 0.7 0:00.45 sshd 1 root 20 0 2900 1408 1204 S 0.0 0.3 0:03.05 init 2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd 3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 4 root 20 0 0 0 0 S 0.0 0.0 0:00.02 ksoftirqd/0 5 root RT 0 0 0 0 S 0.0 0.0 0:00.00 stopper/0 6 root RT 0 0 0 0 S 0.0 0.0 0:00.02 watchdog/0 7 root 20 0 0 0 0 S 0.0 0.0 0:00.19 events/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 events/0 9 root 20 0 0 0 0 S 0.0 0.0 0:00.00 events_long/0 10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 events_power_ef 11 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cgroup 12 root 20 0 0 0 0 S 0.0 0.0 0:00.00 khelper 13 root 20 0 0 0 0 S 0.0 0.0 0:00.00 netns 14 root 20 0 0 0 0 S 0.0 0.0 0:00.00 async/mgr 15 root 20 0 0 0 0 S 0.0 0.0 0:00.00 pm 16 root 20 0 0 0 0 S 0.0 0.0 0:00.00 sync_supers 17 root 20 0 0 0 0 S 0.0 0.0 0:00.00 bdi-default 18 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kintegrityd/0 19 root 20 0 0 0 0 S 0.0 0.0 0:00.21 kblockd/0 20 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kacpid 21 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kacpi_notify 22 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kacpi_hotplug 23 root 20 0 0 0 0 S 0.0 0.0 0:00.00 ata_aux 24 root 20 0 0 0 0 S 0.0 0.0 0:00.02 ata_sff/0 25 root 20 0 0 0 0 S 0.0 0.0 0:00.00 ksuspend_usbd 26 root 20 0 0 0 0 S 0.0 0.0 0:00.01 khubd
直接在命令行输入top回车之后就可以看到上面的效果了,内容是不是很丰富,先逐个介绍参数的含义。
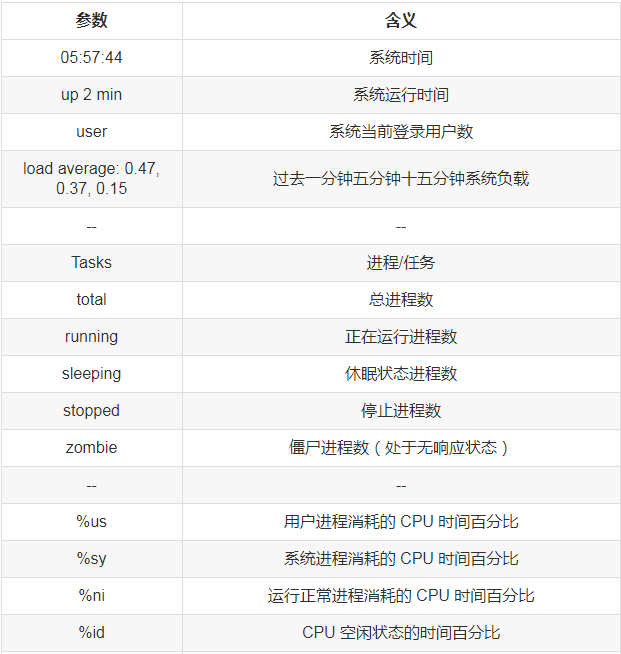
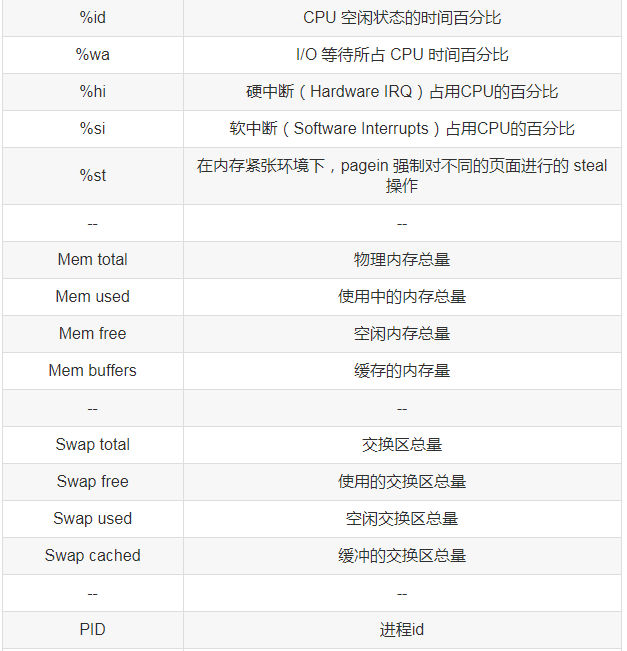
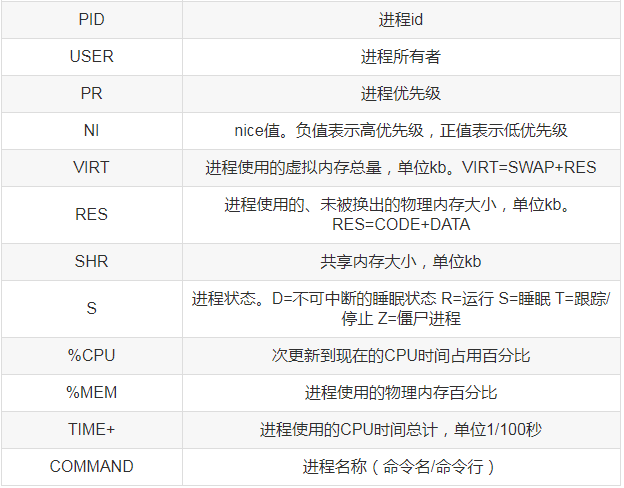
其实不难发现,top包含了前面介绍的一些命令的结果,如uptime、free、iostat等,那除了内容比较全面之外,top还提供了一些交互操作,让我们能更进一步的分析系统性能。
下面我介绍几个常用的交互操作:
展开Cpu(s)
在top交互界面直接按键盘的数字1。
这里还是要强调一下,%cpu的值是跟内核数成正比的,如8核cpu的%cpu最大可以800%。显示线程
在top交互界面按ctrl+h显示线程,再按一次关闭显示。帮助
在top交互界面按h进入帮助界面。增加或删除显示列
在top交互界面按h进入,输入想显示的列的首字母如n,退出直接回车。排序
Cpu : 在top交互界面按shift+p。
Mem :在top交互界面按shift+m。
Time :在top交互界面按shift+t。显示程序名
在top交互界面按c。监控进程下的线程
在命令行输入top -H -p pid,其中pid为进程id,进入界面后显示的PID为线程ID;或者使用命令top -H -p pid进入界面之后在按shift+h来显示线程。
netstat
Netstat 命令用于显示本机网络连接、运行端口、路由表等信息,常用命令有两个netstat -plnt和netstat -i,我们来看看。
[root@localhost~]# netstat -iKernel Interface table Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth1 1500 0 4249 0 0 0 5786 0 0 0 BMRU lo 65536 0 0 0 0 0 0 0 0 0 LRU
Iface:表示网络设备的接口名称。
MTU:表示最大传输单元,单位为字节。
RX-OK/TX-OK:表示已经准确无误地接收/发送了多少数据包。
RX-ERR/TX-ERR:表示接收/发送数据包时候产生了多少错误。
RX-DRP/TX-DRP:表示接收/发送数据包时候丢弃了多少数据包。
RX-OVR/TX-OVR:表示由于误差而丢失了多少数据包。
Flg 表示接口标记,其中
B 已经设置了一个广播地址。
L 该接口是一个回送设备。
M 接收所有数据包(混乱模式) 。
N 避免跟踪。
O 在该接口上,禁用 AR P。
P 这是一个点到点链接。
R 接口正在运行。
U 接口处于“活动”状态。其中 RX-ERR/TX-ERR、 RX-DRP/TX-DRP 和 RX-OVR/TX-OVR 的值应该都为 0,如果不为 0,并且很大,那么网络质量肯定有问题,网络传输性能也一代会下降。
[root@localhost~]# netstat -plntActive Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1073/sshd tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1152/master tcp 0 0 :::3306 :::* LISTEN 1623/mysqld tcp 0 0 :::80 :::* LISTEN 1209/httpd tcp 0 0 :::21 :::* LISTEN 1265/proftpd tcp 0 0 :::22 :::* LISTEN 1073/sshd tcp 0 0 ::1:25 :::* LISTEN 1152/master tcp 0 0 :::443 :::* LISTEN 1209/httpd
Proto :协议
Recv-Q:表示接收队列。
Send-Q :表示发送队列。
LocalAddress :表示本地机器名、端口
Foreign Address :表示远程机器名、端口
State:表示状态,其中
LISTEN :在监听状态中。
ESTABLISHED:已建立联机的联机情况。
TIME_WAIT:该联机在目前已经是等待的状态。PID/Program name:进程id/进程名
strace
strace 常用来跟踪进程执行时的系统调用和所接收的信号。 在 Linux 世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace 可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
那在什么情况下需要用到strace呢?比如用户CPU高的时候,你可以通过dump线程栈等方式进行深入分析,而系统CPU高时,先分析I/O,此时如果I/O高那么就可以确定是I/O问题了,如果I/O不高,那么想进一步分析就需要用到strace啦。
[root@localhost~]# strace -c -f -r -t -p 1724Process 1724 attached^CProcess 1724 detached% time seconds usecs/call calls errors syscall------ ----------- ----------- --------- --------- ---------------- 100.00 0.000039 20 2 read 0.00 0.000000 0 2 write 0.00 0.000000 0 3 select 0.00 0.000000 0 8 rt_sigprocmask------ ----------- ----------- --------- --------- ---------------- 100.00 0.000039 15 total
以上命令中-p 172的172指的是你的进程id。
% time :调用该行命令占总时间的百分比
Seconds :调用总时长
usecs/call :用户调用次数
Calls:系统调用次数
Errors:错误总数
Syscall:调用的内核命令
总结
篇幅比较长,读起来难免枯燥,学习linux监控我认为首先要知道它有哪些命令,分别能做什么,其次要掌握每个命令的用法,最后一定要了解命令输出参数的含义。做到以上几点,我觉得你就已经具备了简单的监控和分析的能力,这个再去使用一些监控工具,就so easy了。
我的答案
CPU、内存以及硬盘的关系?
我们都知道,CPU是计算机的大脑,主要负责计算和逻辑判断,且自带一块容量比较小的高速缓存区,内存是CPU运行时数据存储的空间,硬盘的作用是数据保存。那么他们的工作流程到底是怎么样的呢,还是先看一个比较形象的例子。
把CPU比喻成车间工人,每个工人看做一个CPU内核,把内存比喻成车间,硬盘比喻成仓库。车间的物件(数据)来自于仓库,车间工人在车间工作,处理车间内的物件(数据),当车间内的物件(数据)处理好后存放回仓库。很明显,车间越大车间工人越多,那么整个工厂单位时间能干的活也就越多。buff和cach的区别?
buff:缓冲区,在进程通信时由于设备读写速度不一致产生,慢的一方先将数据存放到buff中,达到一定程度存储快的设备再读取buffer的数据,通过buffer可以减少进程间通信需要等待的时间。
cache:缓存区,高速缓存,位于CPU和主内存之间的容量较小但速度很快的存储器,它减少了CPU等待的时间。线程与进程的区别及优缺点?
一个进程包含至少一个线程,进程是资源集合体,是系统资源分配调度的基本单位,线程是进程的执行单元,进程和线程都可以并发,进程在执行过程中拥有独立的内存单元,而线程之间共享内存
标签:
上一篇: Nginx高并发优化方案(血荐!)
下一篇: mongoTemplate实战
