clickhouse 安装
楔子
相较于 Hadoop 生态圈中的一些系统,ClickHouse 的安装显得尤为简单,因为它自成一体,在单节点的情况下不需要额外的依赖,集群的话后面会说。
ClickHouse 支持运行在主流 64 位 CPU 架构的 Linux 操作系统上,可以通过源码编译、预编译压缩包、Docker 镜像和 RPM 等多种方法进行安装。这里我们着重介绍一下离线 RPM 的安装方法,因为它最常用。
这里我使用的系统是 CentOS 7.6。
1)下载 RPM 安装包
RPM 包可以从仓库 https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/ 中进行下载,里面包含了所有版本的 ClickHouse,这里我选择的版本是 21.7.3.14-2。因此需要下载如下文件:
clickhouse-client-21.7.3.14-2.noarch.rpm clickhouse-common-static-21.7.3.14-2.x86_64.rpm clickhouse-common-static-dbg-21.7.3.14-2.x86_64.rpm clickhouse-server-21.7.3.14-2.noarch.rpm
2)关闭防火墙并检查环境依赖
考虑到后续的集群部署,通常建议关闭本机的防火墙,在 CentOS 7 中关闭防火墙的方法如下:
# 关闭防火墙systemctl stop firewalld.service# 禁用开机启动项systemctl disable firewalld.service
接着需要验证当前服务器的 CPU 是否支持 SSE 4.2 指令集,因为向量化执行需要用到这项特性:
grep -q sse4_2 /proc/cpuinfo && echo "支持 SSE 4.2 指令集" || echo "不支持 SSE 4.2 指令集"

如果不支持 SSE 指令集,则不能使用上面下载的 RPM 安装包,而是需要使用源码编译的方式安装,当然现在的 CPU 基本上都是支持的。
3)安装 ClickHouse
我们将上面下载的 RPM 包上传到服务器,然后进行安装。
# 使用通配符,会将当前目录下所有的 rpm 包依次安装,非常方便# 因为我们是安装 ClickHouse,所以该目录除了 ClickHouse 的 rpm 包之外,最好不要有其它的 rpm 包rpm -ivh ./*.rpm
注意,在安装到 clickhouse-server 的时候会提示你设置密码:

因为 ClickHouse 在安装的时候会有一个默认的 default 用户,这里会提示你给 default 设置密码,因为 ClickHouse 和 MySQL、PostgreSQL 等数据库一样,也具有用户管理权限。老版本默认没有密码,新版本会让你主动设置,这里我们就不设置了,直接回车就好,这样后续在连接的时候就不需要密码了。
最后,如果想卸载 ClickHouse 也很简单,只需以下几步:
yum remove clickhouse-client clickhouse-common-static clickhouse-common-static-dbg clickhouse-server -yrm -rf /var/lib/clickhouserm -rf /etc/clickhouse-*rm -rf /var/log/clickhouse-server
目录结构
程序在安装的时候会自动构建整套目录结构,接下来分别说明它们的作用。
1) 首先是核心目录部分
/etc/clickhouse-server:服务端的配置文件目录, 包括全局配置 config.xml 和用户配置 users.xml 等。
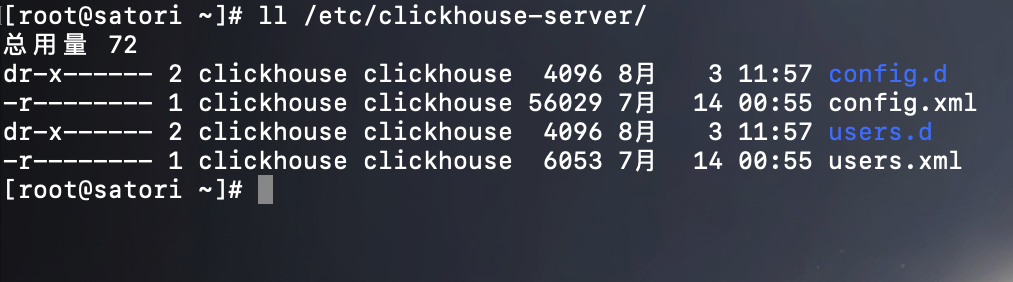
/var/lib/clickhouse:默认的数据存储目录(通常会修改默认存储路径,将数据保存到大容量磁盘挂载的路径),通过 config.xml 进行修改。
/var/log/clickhouse-server:默认保存日志的目录(通常会修改默认存储路径,将日志保存到大容量磁盘挂载的路径),通过 config.xml 进行修改。
2) 接下来是配置文件部分
/etc/security/limits.d/clickhouse.conf:文件句柄数量的配置,默认值如下所示:
[root@satori ~]# cat /etc/security/limits.d/clickhouse.confclickhouse soft nofile 262144 clickhouse hard nofile 262144 [root@satori ~]#
该配置也可以通过 config.xml 中的 max_open_files 参数指定。
/etc/cron.d/clickhouse-server:cron 定时任务配置,用于恢复异常中断的 ClickHouse 服务进程,其默认的配置如下所示:
[root@satori ~]# cat /etc/cron.d/clickhouse-server#*/10 * * * * root ((which service > /dev/null 2>&1 && (service clickhouse-server condstart ||:)) || /etc/init.d/clickhouse-server condstart) > /dev/null 2>&1[root@satori ~]#
可以看到默认每隔 10 秒就会使用 condstart 尝试启动一次 ClickHouse 服务,如果 ClickHouse 服务正在运行,则跳过;如果没有运行,则启动。
3) 最后是在 /usr/bin 目录下的启动文件
ClickHouse 相关的启动文件都位于 /usr/bin 目录下。

可执行文件数量还是蛮多的,其中四个最常用。
clickhouse: 主程序的可执行文件clickhouse-client: 一个指向 ClickHouse 可执行文件的软连接, 供客户端连接使用clickhouse-server: 一个指向 ClickHouse 可执行文件的软连接, 供服务端启动使用clickhouse-compressor: 内置提供的压缩工具, 可用于数据的正压反解
启动命令
ClickHouse 给我们提供了非常优雅的启动方式。
启动 ClickHouse:clickhouse start
关闭 ClickHouse:clickhouse stop
重启 ClickHouse:clickhouse restart
注意:在安装 ClickHouse 的时候,系统会自动创建一个名为 clickhouse 的用户,启动脚本会基于此用户来启动服务。因此我们需要让 clickhouse 用户具备相关目录的权限,如果不赋权限,ClickHouse 可能会启动失败。
chown clickhouse.clickhouse /var/log/clickhouse-server/ -R chown clickhouse.clickhouse /var/lib/clickhouse/ -R # 如果后续你修改了配置文件,改变了 ClickHouse 的数据存储目录,那么也要记得赋给它相应的权限
另外,上面通过 clickhouse start 启动的时候我们没有指定配置文件,没错,通过这种方式启动的话,会自动加载 /etc/clickhouse-server/config.xml。
但如果我们想手动指定配置文件的话,那么需要使用 clickhouse-server。
clickhouse-server --config-file /etc/clickhouse-server/config.xml --daemon
--config-file 负责指定配置文件,这样即使将配置文件放在了别的地方也没有关系,因为我们可以显式地指定它的位置;--daemon 表示后台启动,因为默认是前台启动的。
但是注意:使用 clickhouse-server 启动的话,不能使用 root 用户,需要切换到 clickhouse 用户,所以我们应该这么做。
sudo -u clickhouse clickhouse-server --config-file /etc/clickhouse-server/config.xml --daemon
注意:sudo -u 后面的 clickhouse 指的是名为 clickhouse 的用户,而 clickhouse start 里面的 clickhouse 指的是 /usr/bin 里面的可执行文件。这里由于我们配置文件就在默认路径下,所以也可以直接使用 clickhouse start 启动,默认加载 /etc/clickhouse-server/config.xml、并且后台启动。至于关闭的话,直接 clickhouse stop 即可。
客户端的访问接口
ClickHouse 服务端的底层访问接口支持 TCP 和 HTTP 两种方式,其中 TCP 拥有更好的性能,默认监听 9000 端口,主要用于集群间的内部通信及 clickhouse-client 客户端的连接;而 HTTP 协议则拥有更好的兼容性,可以通过 REST 服务的形式被广泛用于编程语言的客户端,默认监听 8123 端口。
下面我们来介绍几种连接方式。
使用客户端 clickhouse-client 连接服务端
通过 clickhouse start 将服务启动之后,我们就可以使用客户端进行连接了,通过 clickhouse-client,默认会连接到本机的 9000 端口,并使用 default 用户,如果想单独指定的话可使用如下方式:
clickhouse-client --host 地址 --port 端口 --user 用户 --password 密码
这里我们的服务端默认监听 9000 端口,并且 default 用户还没有密码,所以直接输入 clickhouse-client 即可连接上。
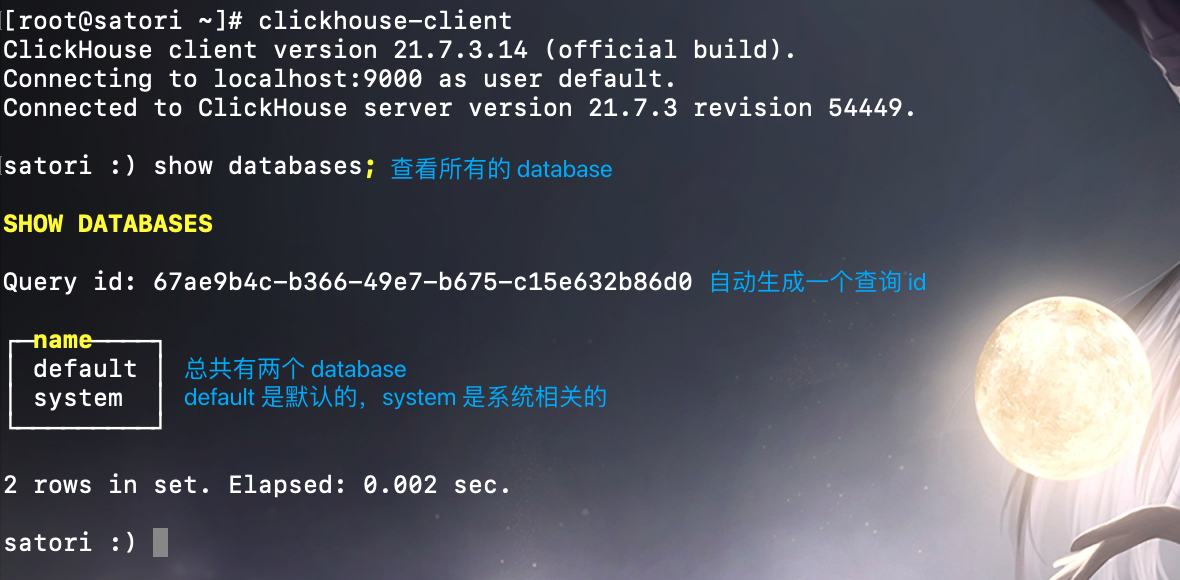
我们看到连接成功,并且也查询成功了,到此单节点 ClickHouse 的安装就算完毕了,至于集群的搭建后面会说。
插句题外话,如果我们想要更新 ClickHouse,那么直接下载新版的 ClickHouse RPM 包即可,然后进行更新:
rpm -Uvh ./*.rpm
升级的时候,原有的配置均会保留。
然后再来补充一下 clickhouse-client 的内容,上面通过输入 clickhouse-client 进入命令行、然后再执行 SQL 的方式叫做 "交互式执行",一般用于调试、运维、开发和测试等场景。通过交互式执行的 SQL 语句,相关查询结果会统一记录到 ~/.clickhouse-client-history 文件中,可以作为审计之用。
但除了交互式执行之外,还有非交互式执行。非交互式执行主要用于批处理场景,诸如对数据的导入和导出操作,在执行脚本命令时,需要追加 --query 参数指定执行的 SQL 语句。举个栗子:
cat xxx.csv | clickhouse-client --query "INSERT INTO some_table FORMAT CSV"
在导入数据时,它可以接收操作系统的 stdin 标准输入作为写入的数据。所以 cat 命令读取的文件流,将会作为 INSERT 语句的数据输入,而在数据导出时,则可以将输出流重定向到文件:
clickhouse-client --query "SELECT * FROM some_table" >> xxx.csv
默认情况下,clickhouse-client 一次只能运行一条 SQL 语句,如果需要执行多次查询,则需要在循环中重复执行,这显然不是一种高效的方式。此时可以追加 --multiquery 参数,它可以支持一次运行多条 SQL 查询,多条查询之间使用分号分隔,比如:
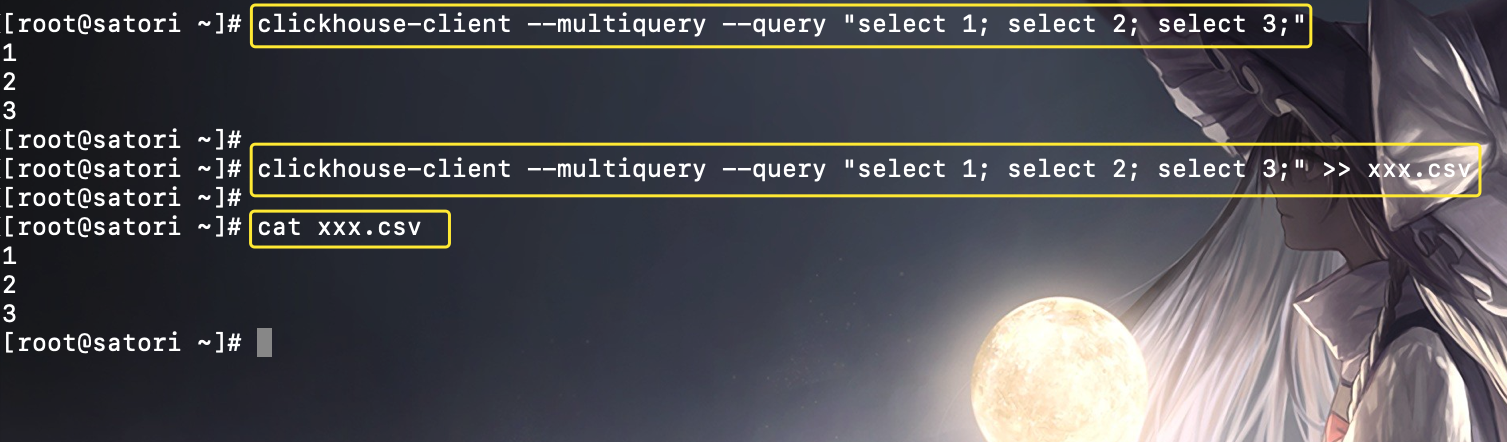
多条 SQL 的查询结果集会依次按照顺序返回。
以上就是 clickhouse-client 的两种运行方式,由于提供了非交互式执行的功能,所以 ClickHouse 的客户端比其它数据库的客户端要强大一些。下面整理一下 clickhouse-client 常用的相关参数:
--host/-h: 指定连接的服务端的地址, 默认是 localhost,如果服务端的地址不是 localhost, 则需要依靠此参数进行指定, 例如 clickhouse-client -h xx.xx.xx.xx--port: 服务端的 TCP 端口, 默认是 9000,如果服务端监听的不是 9000, 则需要此参数指定--user/-u: 登录的用户名, 默认是 default。如果使用非 default 的用户名登录, 则需要使用此参数指定--password: 登录的密码, 默认值为空。如果在用户定义中未设置密码, 则无需填写(比如默认的 default 用户,我们没有设置密码)--database/-d: 登录之后所在的数据库, 默认为 default--query/-q: 只能在非交互式查询时使用, 用于执行指定的 SQL 语句--multiquery/-n: 在非交互式执行时, 允许一次运行多条 SQL 语句, 多条语句之间用分号隔开--time/-t: 在非交互式执行时, 会打印每条 SQL 的执行时间
更多参数可以通过 clickhouse-client --help 查看,数量多到恐怖。
Python 连接 ClickHouse 服务端
首先 ClickHouse 支持使用 JDBC 连接,但我本身不是 JAVA 方向的,所以这里只介绍使用 Python 连接 ClickHouse 的方式。
Python 连接 ClickHouse 的话需要安装一个第三方库,直接 pip install clickhouse-driver 即可。
注意:我们说 HTTP 协议使用的是 8123 端口,但 Python 这个包比较特殊,它和 clickhouse-client 一样,使用的也是 TCP 协议,也就是说端口需要指定为 9000。
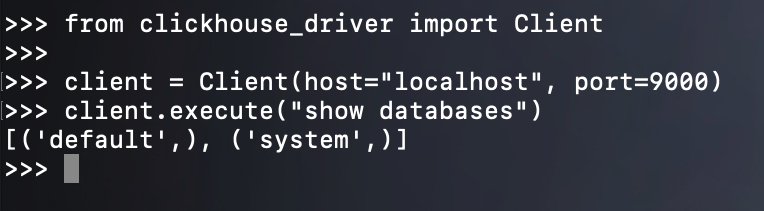
使用 Python 是可以连接的,但是注意:我们这里是在服务器上使用 Python 连接的,如果需要在其它机器上连接的话,那么就不能使用 localhost 了。
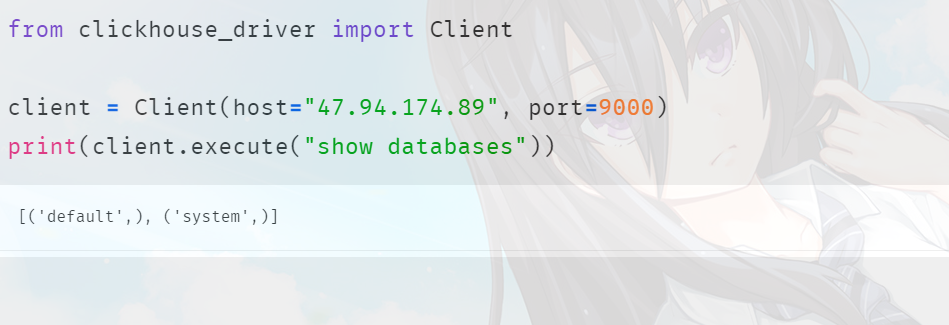
from clickhouse_driver import Client# 需要指定具体的 ipclient = Client(host="47.94.174.89", port=9000)print(client.execute("show databases"))不过此时仍无法在其它节点上访问,因为我们还需要修改一下服务端的配置,vim /etc/clickhouse-server/config.xml:
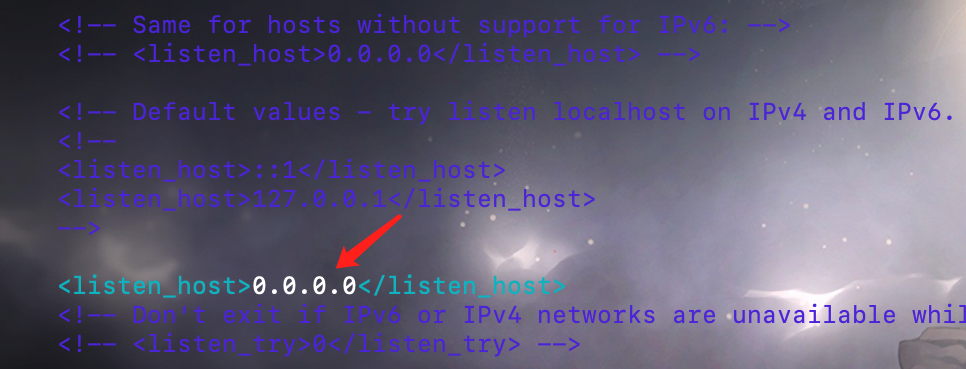
listen_host 这个标签默认是被注释掉的,也就是只监听来自本机的请求。这里我们将注释打开,或者不管注释,直接手动增加一条。
<!-- 改成 0.0.0.0,这样即可接收来自其它机器上的请求 --><listen_host>0.0.0.0</listen_host>
此时 Python 即可在其它节点上访问了,注意:服务器的 9000 端口要对外开放。
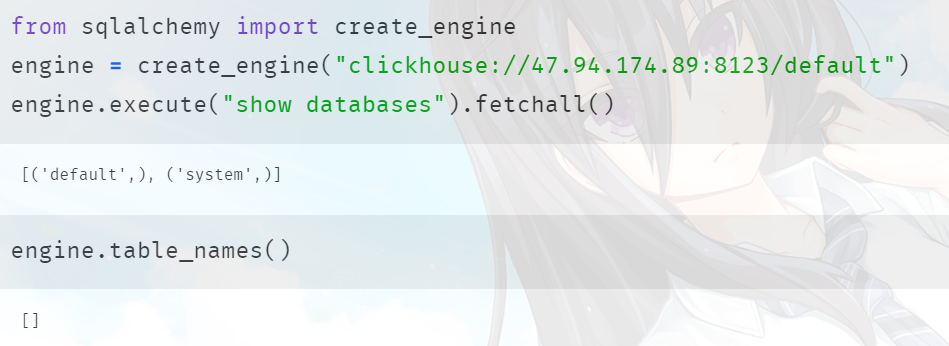
此外我们还可以通过 sqlalchemy 去连接,但是默认情况下 sqlalchemy 找不到对应的 dialect,所以需要再安装一个模块:pip install sqlalchemy_clickhouse,安装之后就可以使用了。但有一点需要注意:使用 sqlalchemy_clickhouse 的话,那么连接的端口就不是 9000 了,而是 8123。更准确的说,需要使用 HTTP 端口。
以上就是 Python 连接 ClickHouse 的两种方式,还是挺容易的。
内置的实用工具
我们说 /usr/bin 下面包含了很多关于 ClickHouse 的启动文件,除了之前介绍的四个,这里再介绍两个,分别是 clickhouse-local 和 clickhouse-benchmark。
clickhouse-local
clickhouse-local 可以独立运行大部分的 SQL 查询,不需要依赖任何 ClickHouse 服务端程序,它可以理解为 ClickHouse 服务的单机版内核,是一个轻量级的应用程序。clickhouse-local 只能使用 File 引擎(关于引擎后面会展开),它的数据与同机运行的 ClickHouse 服务之间也是完全隔离的,不能互相访问。
clickhouse-local 是非交互式的,每次执行都需要指定数据来源,例如通过 stdin 标准输入,以 echo 打印作为数据来源:

也可以借助操作系统的命令,实现对系统用户内存使用量的查询。
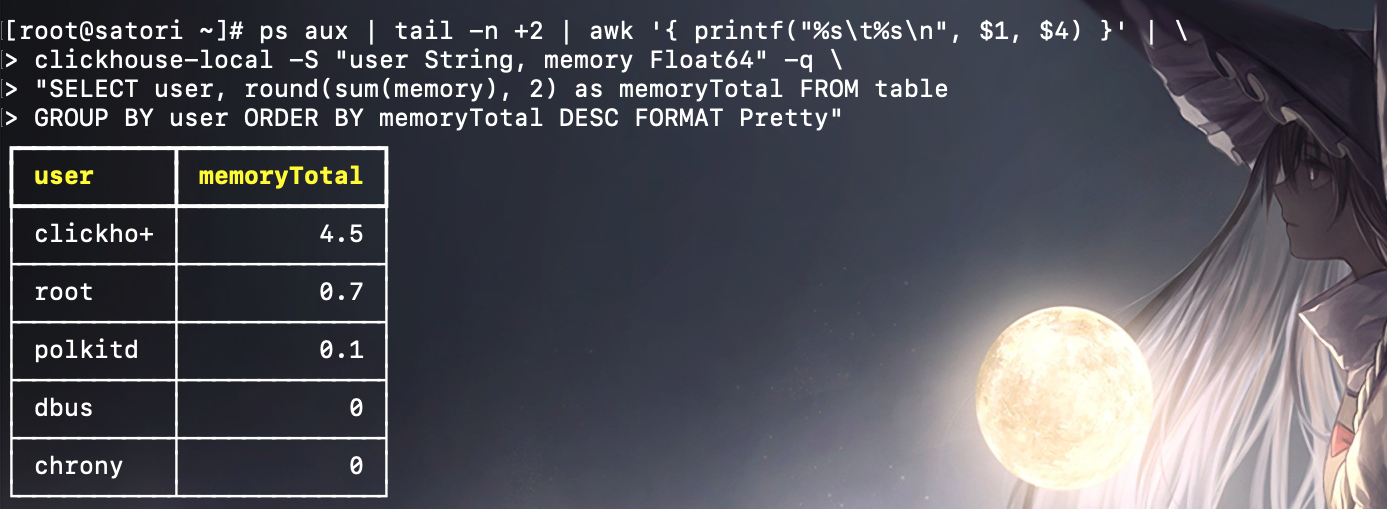
clickhouse-local 的参数用法可以通过 --help 查看,但个人觉得不是很常用。
clickhouse-benchmark
clickhouse-benchmark 是基准测试的小工具,它可以自动运行 SQL 查询,并生成对应的运行指标报告,例如执行下面的语句启动测试:
echo "SELECT * FROM table" | clickhouse-benchmark -i 5
按照指定参数的查询会被执行 5 次,执行完毕之后,会显示包含 QPS、RPS 等指标信息的报告,还会列出各百分位的查询执行时间。
如果想测试多条 SQL,此时就需要将 SQL 写在文件中,然后通过 clickhouse-benchmark -i 5 < 文件路径,将里面的 SQL 按照顺序依次执行。
这里我就不使用具体的数据测试了,有兴趣可以自己尝试一下。
clickhouse-benchmark 的一些核心参数可以通过 --help 查看。
小结
以上我们就介绍了基于离线 RPM 包安装 ClickHouse 的整个过程,当然也可以使用其它方式安装,比如在线安装、使用 Docker 安装等等。事实上,这种离线安装的方式也不麻烦,相反个人觉得还很简单。然后还介绍了访问 ClickHouse 的两个接口:TCP 接口和 HTTP 接口,以及如何使用 Python 去访问。
下一篇文章我们就来学习 ClickHouse 的具体语法了,首先会从数据定义开始。
原文:https://www.cnblogs.com/wan-ming-zhu/p/18092504
标签:
上一篇: Docker 搭建 Minio 容器 (完整详细版)
下一篇: 纯真社区版IP库
